On the consistency of IPW methods to recover causal effects from selection bias
Published
March 1, 2023
Confounding bias and selection bias are together the most prevalent hurdles to the validity and generalizability of causal inference results. In general, both arise from uncontrolled extraneous flows of statistical information between treatment and outcome in the analysis. Their precise characterization in the Structural Causal Models framework (SCM), and potential corrections, differ in nature:
Confounding bias emerges from open backdoor paths between treatment and outcome in the directed acyclic graph (DAG) that represents the set of assumptions on the system’s causal mechanisms. In experimental settings, (conditional) randomization of treatment assignment provides a practical solution to the problem. In observational studies, the do-calculus, developed by Judea Pearl (Pearl 2009), constitute a complete and formal set of graphical rules to test the identifiability of the target causal parameters.
Selection bias emerges from the preferential exclusion of units from the sample under analysis. It implies conditioning on a collider (or a descendant of a virtual collider), which opens backdoor paths between treatment and outcome. Besides, distributions learnt from the biased samples might not generalize to the whole population. Selection bias cannot be removed via randomization, which makes it a concern for experimental settings as well. There exist extensions of the do-calculus to deal with selection bias in some cases. Inverse probability weighting (IPW) methods are more frequently used in applied work.
Corrections for selection bias
Inverse probability weighting (IPW) methods provide nonparametric statistical techniques to perform inference with biased data. In their basic presentation, they approximate the interventional mean of the outcome using a weighted average over the selected sample. Let:
\((y_i)_{i=1}^N\) be a sample of outcomes for the selected (non-excluded) units
\(w_i\) be the relative inverse probability of selection, \(w_i=p/p_i\), where \(p\) is the population-level probability of selection, and \(p_i\) is the probability of selection for unit \(i\)
\(v_i(a)\) be the inverse probability of assignment of treatment \(a\) for unit \(i\)
The idea of IPW methods is motivated by the desired asymptotic result:
The derived finite-sample estimator is consistent if \(v_i(a)\cdot w_i\) is; this is, if the probability of selection and the probability of treatment assignment are jointly correctly specified.
Let us analyse the results of an IPW-based approach on a simple simulation with a randomized treatment assignment and when:
the selection mechanism only hides the outcome. This is, only \(Y\) is missing when \(S=0\)
the selection mechanism does not depend on a mediator
Simple simulation setting
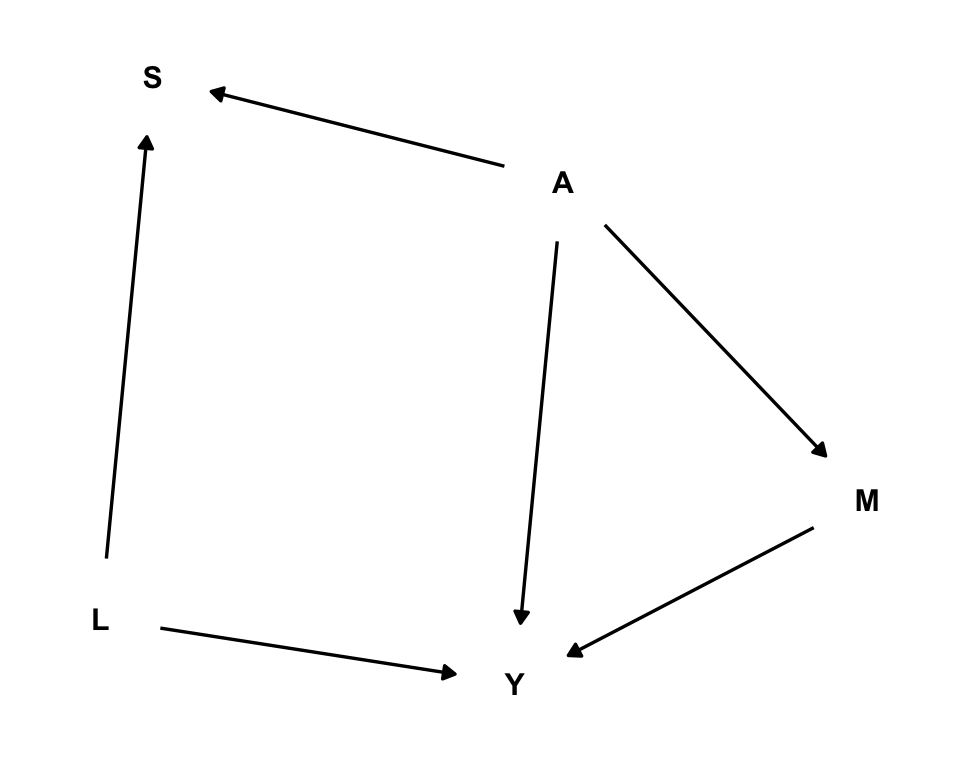
Let us consider the SCM given by the following DAG and set of structural equations:
The DAG:
Code
# DAG visualizationlibrary(ggplot2)library(dagitty)library(ggdag)dagify( M ~ A, S ~ A + L, Y ~ A + M + L) %>%tidy_dagitty(layout ="nicely") %>%ggplot(aes(x = x, y = y, xend = xend, yend = yend)) +geom_dag_point(color='white',size=0.5) +geom_dag_edges() +geom_dag_text(color='black') +theme_dag()
When \(S=1\) for a particular unit, we get to observe their whole data \((L,A,M,Y)\). When \(S=1\), only the final outcome \(Y\) is missing, so we get to observe \((L,A,M)\).
Let us put this SCM as a data-generating process (DGP) in R code:
Code
# Libraries neededlibrary(DescTools)library(LaplacesDemon)library(dplyr)library(kableExtra)library(modelsummary)library(gt)library(zeallot)library(reshape2)# Data generating processdgp =function(param){#### Parametersc(n, # Number of samples sdl, # Stdr. dev. of selection predictor p, # Treatment assigment probability a0, a1, # Parameters of A->M relation sdm, # Stdr. dev. of mediator noise g0, g1, # Parameters of A->S relation g2, # Parameter of M->S relation g3, # Parameter of L->S relation sds, # Stdr. dev. of selection noise b0, b1, # Parameters of A->Y relation b2, # Parameter of M->Y relation b3, # Parameter of L->Y relation sdy # Stdr. dev. of selection noise ) %<-% param # Exogenous selection predictor L =rnorm(n=n, mean=0, sd=sdl)# Treatment assigment A =rbinom(n=n, size=1, prob=p)# Mediator noise.M =rnorm(n=n, mean=0, sd=sdm) M = a0 + a1*A + noise.M# Selection mechanism noise.S =rnorm(n=n, mean=0, sd=sds) S =ifelse(g0 + g1*A + g2*M + g3*L + noise.S >0, 1, 0)# Outcome noise.Y =rnorm(n=n, mean=0, sd=sdy) Y = b0 + b1*A + b2*M + b3*L + noise.Y# true ATE true.ATE = b1 + b2*a1# Data dat =data.frame(L,A,M,S,Y)# Returnreturn(list(dat,true.ATE))}
Simulation excercise
This case of \(M\) not being a direct cause of \(S\) is equivalent to setting \(\gamma_2=0\) in the structural equation of the selection mechanism \(S\). Let us simulate some noisy data:
Code
# Set random seedset.seed(7)# Parameters valuesparam.1=c(n=1e3, # Number of samplessdl=1, # Stdr. dev. of selection predictorp=0.5, # Treatment assigment probabilitya0=0.1, a1=0.5, # Parameters of A->M relationsdm=0.4, # Stdr. dev. of mediator noiseg0=-0.1, g1=0.2, # Parameters of A->S relationg2=0, # Parameter of M->S relation ### M DOES NOT CAUSE Sg3=0.2, # Parameter of L->S relationsds=0.5, # Stdr. dev. of selection noiseb0=-1.5, b1=0.5, # Parameters of A->Y relationb2=0.5, # Parameter of M->Y relationb3=1.8, # Parameter of L->Y relationsdy=2.7) # Stdr. dev. of selection noise# Generate datadgp.1=dgp(param.1)# Save the full datadat.1= dgp.1[[1]]# Save the true ATET.ATE = dgp.1[[2]]# Glimpse of the datahead(dat.1) %>%kbl() %>%kable_styling(full_width = F)
For a moment let us pretend we observe all variables for everyone. Let us examine the most interesting models that we can fit with the simulated data, to check their ability to recover population-level parameters under noisy samples.
Code
# Model for M, with complete datamod.M =lm(M ~ A, data=dat.1)# Model for S, with complete datamod.S =glm(S ~ A + L, family=binomial('probit'), data=dat.1)# Model for Y, with complete datamod.Y =lm(Y ~ A + M + L, data=dat.1)# Model for causal effect, with complete data# Version 1: Controlling for predictor of Ymod.ate.1=lm(Y ~ A + L, data=dat.1)# Model for causal effect, with complete data# Version 2: Treatment is randomized, no controls neededmod.ate.2=lm(Y ~ A, data=dat.1)# All models put togethermodels.full =list("M"= mod.M, "S"= mod.S, "Y"= mod.Y, "ATE (O-set)"= mod.ate.1, "ATE (no adj)"= mod.ate.2)# Summary of modelsmodelsummary(models.full, statistic ="[{conf.low}, {conf.high}]",estimate ="{estimate}{stars}")
M
S
Y
ATE (O-set)
ATE (no adj)
(Intercept)
0.104***
−0.107+
−1.579***
−1.498***
−1.524***
[0.069, 0.139]
[−0.219, 0.005]
[−1.816, −1.342]
[−1.732, −1.263]
[−1.803, −1.245]
A
0.506***
0.296***
0.281
0.677***
0.742***
[0.456, 0.556]
[0.135, 0.457]
[−0.114, 0.675]
[0.340, 1.013]
[0.342, 1.141]
L
0.427***
1.755***
1.768***
[0.341, 0.514]
[1.584, 1.925]
[1.597, 1.940]
M
0.784***
[0.369, 1.200]
Num.Obs.
1000
1000
1000
1000
1000
R2
0.283
0.311
0.301
0.013
R2 Adj.
0.282
0.308
0.300
0.012
AIC
1022.7
1278.2
4824.1
4835.8
5178.8
BIC
1037.5
1292.9
4848.7
4855.5
5193.5
Log.Lik.
−508.364
−636.108
−2407.072
−2413.913
−2586.403
RMSE
0.40
0.47
2.69
2.70
3.21
Since the treatment is randomized, no control variables are required in the regression of \(Y\) against \(A\) to remove confounding bias. However, \(L\) is in the \(O\)-set of the effect; this is, controlling for \(L\) produces an asymptotically more efficient estimator. Such property is not seen in finite samples [see last two models].
It is no surprise that, with complete data, the point-estimate for the coefficient of \(A\) in the last two models lie close to the true ATE (0.75), even under a moderately noisy DGP (\(R^2\approx 0.3\)).
Results under exclusion
Ignoring samples for which \(S=0\) reduces sample size from 1000 to 514. This is, the probability of exclusion is about 0.486.
Code
# Number of observation per selection# 1 = selected / observed# 0 = excludedtable(dat.1$S) %>%kbl(col.names =c('S','N')) %>%kable_styling(full_width = F)
S
N
0
486
1
514
In contrast with the complete data case, a regression-based approach for estimating the ATE with only the selected samples does require controlling for \(L\), since conditioning on \(S\) opens the non-causal path:
Unfortunately, controlling for \(L\) alone does not remove selection bias, despite blocking such path. This is because the distribution of\(L\)in the sample does not necessarily match the distribution in the population.
Let us inspect it.
Regression-based approach:
We fit a model for the outcome \(Y\) against \(A\), controlling for \(L\), using only the selected samples:
Code
# Data for the selected sampledat.s = dat.1%>%filter(S==1)N.s =nrow(dat.s)# Model for causal effect, with selectedmod.ate.s =lm(Y ~ A + L, data=dat.s)modelsummary(list("ATE(S=1)"= mod.ate.s), statistic =NULL,estimate ="{estimate}{stars} [{conf.low}, {conf.high}]")
ATE(S=1)
(Intercept)
−1.341*** [−1.688, −0.995]
A
0.516* [0.058, 0.974]
L
1.843*** [1.601, 2.085]
Num.Obs.
514
R2
0.307
R2 Adj.
0.304
AIC
2458.1
BIC
2475.0
Log.Lik.
−1225.026
RMSE
2.62
The resulted 95% confidence interval for the coefficient of \(A\), using only samples for which \(S=1\), still covers the true ATE (0.75). Yet, a downwards bias shrinks the point-estimate and its lower bound noticeably. Using this, we would conclude the ATE is smaller than what truly is.
Let us implement an IPW-based approach to compare against:
IPW-based approach:
Given the SCM, and the assumption of \(\gamma_2=0\), we can express:
\(v_i(a)=1/\mathbb{P}(A=a) = 1/q\) because treatment is randomized
The derived finite-sample estimator of the mean counterfactuals / potential outcomes is: \[
\hat{Y}^a = N^{-1}\sum_{i=1}^N\frac{\mathbb{I}(A_i=a)\cdot\hat{\mathbb{P}}(S=1)}{\hat{\mathbb{P}}(A=a)\cdot\hat{\mathbb{P}}(S=1\mid A=a_i,L=l_i)}\cdot y_i
\]
Putting all ingredients together we get point-estimates \(\hat{Y}^1=\hat{\mathbb{E}}[Y\mid do(A=1)]\) and \(\hat{Y}^0=\hat{\mathbb{E}}[Y\mid do(A=0)]\):
Code
# Compute the probability of selecton for all the units selected# We leverage the model mod.S, trained on complete data since S, A and L are# always observed (Y is the only one missing) and predict only on the selected unitsprob.s.unit =predict(mod.S, newdata=dat.s, type='response')# The unconditional probability of selection can be consistently estimated #... with counts from the total sample size and selected sample sizeprob.s =nrow(dat.s) /nrow(dat.1)# Since the treatment is randomized, the propensity score in the population is known at 0.5. # It can also be estimated from counts in the complete dataset# prop.score = sum(dat.1$A==1)/nrow(dat.1)prop.score =0.5# Estimated counterfactuals/potential outcomes via IPPWest.PO = dat.s %>%mutate(prob.s.unit =as.numeric(prob.s.unit),prob.s =as.numeric(prob.s),prop.score =as.numeric(prop.score),pro.weight = (A/prop.score) + (1-A)/(1-prop.score),weights = pro.weight * prob.s * (1/prob.s.unit),weighted.Y = weights * Y) %>%group_by(A) %>%summarise('PO'=sum(weighted.Y)/N.s)# Print resulted estimateshead(est.PO) %>%kbl() %>%kable_styling(full_width = F)
A
PO
0
-1.4318076
1
-0.7537995
Which, can be used to compute a point-estimate of the ATE: \(\hat{ATE}=\hat{Y}^1-\hat{Y}^0\):
We can see that the IPW-based approach produces a point-estimate closer to the true ATE. To get valid confidence intervals, however, a bootstrapping or asymptotic analysis need to be invoked. We can compute naïve confidence interval without resampling, using the fact:
\[
\hat{\text{var}}(\hat{\text{ATE}}) \geq \hat{\text{var}}(\hat{Y}^1)+\hat{\text{var}}(\hat{Y}^0)=(N-2)^{-2}\sum_{a\in\{0,1\}}\sum_{i=1}^N \mathbb{I}(A_i=a)\cdot \hat{v}_i(a)^2\hat{w}_i^2(y_i-\hat{Y}^a)^2
\]Such variance is naïve in the sense that it is overconfident due to ignoring the covariance between the potential outcomes, and the higher-order contributions of the weighting factors in the total variance. Anyway, using it will get us:
As noted, the naïve confidence interval is tighter than those produced by inference on the complete data. This means such confidence interval is not statistically valid, but it can still help us visualize the convergence of IPW estimator.
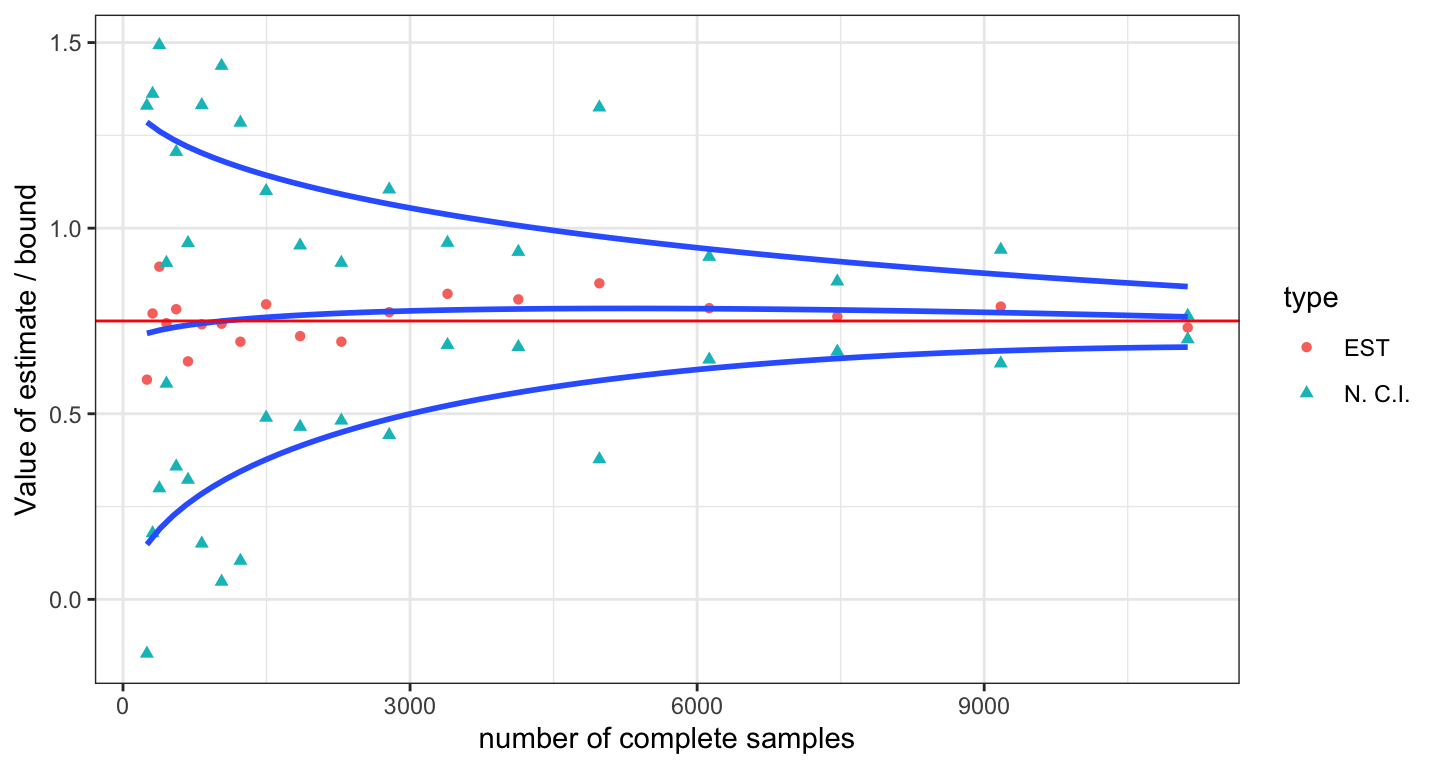
Now, if we simulate and repeat the DGP and same analysis for different sample sizes, consistency would be visually perceived if we see:
Point-estimate converging to the true ATE
Confidence intervals shrinking at a fast (**) rate
Let us test it. We run 20 simulations with different complete sample sizes, from \(N=500\) to \(N=23\,000\) [number of complete samples from \(N_s=250\) to \(N_s=12\,000\)]. We repeat the procedure three times and average the results on those three repetitions. Such averages are presented in the following table:
Code
# Data frame to save results from iterationsrounds.IPPW =data.frame(N=NA, Ns=NA, EST=NA, LB=NA, UB=NA)# All sample sizes to considersamplesizes =round(500*exp(0.2*(0:19)))# Number of repetitionsM =3# Paramaters are the same as beforeparam.iter = param.1# Seedset.seed(66)# Loopfor(m in1:M){for(n in samplesizes){# Change sample size param.iter[1] = n# Generate the data (complete and selected) dat.iter =dgp(param.iter)[[1]] dat.s.iter = dat.iter %>%filter(S==1)# Estimated probability of selection N.s.iter =nrow(dat.s.iter) prob.s.iter = N.s.iter / n# Model for S, with complete data mod.S.iter =glm(S ~ A + L, family=binomial('probit'), data=dat.iter) prob.s.unit.iter =predict(mod.S.iter, newdata=dat.s.iter, type='response')# Propensity score model prop.score.iter =sum(dat.iter$A==1)/nrow(dat.iter)# Put everything together row.iter = dat.s.iter %>%mutate(prob.s.unit =as.numeric(prob.s.unit.iter),prob.s =as.numeric(prob.s.iter),prop.score =as.numeric(prop.score.iter),pro.weight = (A/prop.score) + (1-A)/(1-prop.score),weights = pro.weight * prob.s * (1/prob.s.unit),weighted.Y = weights * Y) # Estimated counterfactuals/potential outcomes via IPPW po.iter = row.iter %>%group_by(A) %>%summarise('Y(A)'=sum(weighted.Y)/N.s.iter)# Estimated ATE ATE.iter =as.numeric(po.iter[2,2]-po.iter[1,2])# Naïve variances sd.PO.iter = row.iter %>%mutate(weighted.var = weights^2* ( A* (Y-po.iter[2,2])^2+ (1-A)* (Y-po.iter[1,2])^2)) %>%group_by(A) %>%summarise('sd'=sqrt(sum(weighted.var))/(N.s.iter-1))# Naïve confidence interval naivebounds =qnorm(0.975)*sum(sd.PO.iter[,2]) rounds.IPPW =rbind.data.frame(rounds.IPPW,data.frame(N=n,Ns=N.s.iter,EST=ATE.iter,LB=ATE.iter-naivebounds,UB=ATE.iter+naivebounds)) }}# Print resulted estimatesrounds.IPPW = rounds.IPPW[-1,] %>%group_by(N) %>%summarise_all(mean)head(rounds.IPPW) %>%kbl() %>%kable_styling(full_width = F)
N
Ns
EST
LB
UB
500
249.6667
0.5919352
-0.1461034
1.3299737
611
309.0000
0.7701710
0.1782066
1.3621354
746
379.6667
0.8962619
0.2991885
1.4933353
911
453.6667
0.7438565
0.5811669
0.9065460
1113
556.0000
0.7817429
0.3579693
1.2055165
1359
679.0000
0.6411555
0.3223225
0.9599884
An the following plot:
Code
### Plot results from roundsrounds.IPPW[,-1] %>%melt(id.vars ='Ns') %>%mutate(type =ifelse(variable=='EST','EST','N. C.I.') ) %>%ggplot(aes(x=Ns,y=value,group=variable)) +geom_point(aes(shape=type,color=type)) +geom_smooth(method = lm, formula = y ~ x +I(sqrt(x)), se =FALSE) +## O(N^0.5) convergencelabs(y='Value of estimate / bound', x='number of complete samples') +geom_hline(yintercept=T.ATE, col ='red') +theme_bw()
We can appreciate that the estimator converges to the true ATE [in red], and its uncertainty reduce at a sustained rate; there is convergence in probability. In other words, the IPW-based estimator is consistent.
Mathematical justification of consistency
We can prove consistency mathematically for this SCM. However, to avoid measure-theoretic conundrums, let us consider the case for which all variables are discrete. Results are generalizable for mixed discrete-continuous cases with positive distributions (no zero-measure events).
Let us assume \(Y\) has support on \(\{y_{(c)}\}_{c=1}^C\), and \(L\) has support on \(\{l_{(k)}\}_{k=1}^K\), then:
Assuming the propensity scores and the probability of selection are both correctly specified, all finite-sample approximations \(\hat{\mathbb{P}}\) converge in the limit to the true distributions \(\mathbb{P}\). Then:
This is, the IPW estimator converges to the true counterfactual mean given by intervention \(do(A=a)\). The last two equalities come from these facts:
\(L\) blocks all non-causal paths from \(A\) to \(Y\) when conditioning on \(S=1\)
\(Y\perp S\,\mid L\) in the back-door graph: the resulting DAG after removing all arrows coming out of \(A\)
\(\mathbb{P}(L=l_{(k)})\) is the population-distribution of \(L\)
Revisiting the regression approach: generalized adjustment criteria
Notice that, in the convergence proof for the IPW estimator, it was shown that the underlying estimand is algebraically equivalent to a regression-adjusted mean of \(Y\), averaged over the population distribution of \(L\).
Extensions of this results are covered by three generalized adjustment criteria(Correa, Tian, and Bareinboim 2018). This is, for this case, a mathematically equivalent result in term of consistency can be achieved via regression adjustment.
References
Correa, Juan, Jin Tian, and Elias Bareinboim. 2018. “Generalized Adjustment Under Confounding and Selection Biases.”Proceedings of the AAAI Conference on Artificial Intelligence 32 (1). https://doi.org/10.1609/aaai.v32i1.12125.