Let \(\mathcal{G}'\) be a directed acyclic graph (DAG) built from domain knowledge and temporal-order constraints, involving the exposure \(A\), the outcome \(Y\), a set of confounders \(H\), and mediators \(M\). We previously fit flexible models (random forests) to learn the causal mechanisms \(\hat{f}_V:\text{supp}\, \text{pa}(V;\mathcal{G}')\times \text{supp}\, U_V\rightarrow\text{supp}\, V\) from real-world data on the subject. This allows us to replicate such mechanisms to generate fake data from seeds (noises and exogenous variables) in a controlled environment, along with counterfactual outcomes. In this exercise, exogenous variables mimic the marginal distribution of their real-world counterpart, but not the joint distribution.
By design, conditional ignorability is satisfied in the synthetic system using the full confounder set. It might not be satisfied in the system where the real-world data come from.
Generated variables can be grouped in three categories:
1. Pre-treatment / exogenous variables and the exposure:
mom.vuln = \(H_1\in\mathbb{R}\) = maternal vulnerability index: a PCA-based index summarizing mother’s diagnoses (+), level of education (-), age (-), and number of children (-)
sex.girl = \(H_2\in\{0,1\}\) = child’s sex at birth, female = 1
med.pre6 = \(H_3\in\{0,1\}\) = prescription for ADHD medication before grade 6
pre.diag = \(H_4\in\{0,1\}\) = diagnoses for comorbid disorders (ADHD-related, internalizing or externalizing) registered before grade 6
ntr.grd5 = \(H_5\in\mathbb{R}\) = raw score obtained at the national test for grade 5 (average math and reading)
reg.gpsp = \(H_6\in\mathbb{N}\) = number of registrations for health services (GP and specialist) before grade 6
med.6to8 = \(A\) = prescription for ADHD medication between grades 6-8
2. Mediator variables and the outcome:
ptr.diag = \(M_1\in\{0,1\}\) = diagnoses for comorbid disorders (ADHD-related, internalizing or externalizing) registered between grades 6-8
ptr.gpsp = \(M_2\in\mathbb{N}\) = number of registrations for health services (GP and specialist) between grades 6-8
ntr.grd8 = \(Y\) = raw score obtained at the national test for grade 8 (math)
3. Counterfactual variables:
ptr.diag.cntr = \(M_1^{1-A}\) = diagnoses for comorbid disorders (ADHD-related, internalizing or externalizing) registered between grades 6-8, had the individual taken the opposite treatment
ptr.gpsp.cntr = \(M_2^{1-A}\) = number of registrations for health services (GP and specialist) between grades 6-8, had the individual taken the opposite treatment
ntr.grd8.cntr = \(Y^{1-A}\) = raw score obtained at the national test for grade 5 (math)
A dataset (synth.data) of \(N=5\,000\) samples was generated:
Code
# Load packages --------------------------------------------------------------library(data.table) # Processes dataframeslibrary(dplyr) # Processes dataframeslibrary(kableExtra) # Styles tableslibrary(speedglm) # Performs fast fitting for GLMlibrary(ranger) # Performs random forest learninglibrary(nnls) # Performs non-negative least squareslibrary(Rsolnp) # Augmented Lagrange optimizerlibrary(sl3) # Performs super-learninglibrary(tmle3) # Performs TMLElibrary(tmle3mediate) # Performs TMLE for mediation analysislibrary(ggplot2) # Plots# Read data -------------------------------------------------------------------load(file="syntheticADHDdata.RData")# Glimpse of the data ---------------------------------------------------------synth.data =data.table(synth.data)synth.data %>%head() %>%kable(caption ="Table 1: A glimpse at the synthetic data")
Table 1: A glimpse at the synthetic data
mom.vuln
sex.girl
med.pre6
pre.diag
ntr.grd5
reg.gpsp
med.6to8
ptr.diag
ptr.gpsp
ntr.grd8
ptr.diag.cntr
ptr.gpsp.cntr
ntr.grd8.cntr
ITE
0.65
0
1
0
19.64
14
0
0
42
16.77
0
44
19.29
2.52
1.31
1
1
0
25.85
1
1
0
21
26.72
0
19
21.64
5.08
0.08
0
1
1
19.59
56
0
0
7
21.38
1
46
23.27
1.89
0.65
0
1
1
15.12
23
1
1
0
17.62
1
0
14.48
3.14
0.99
1
0
1
9.30
27
0
0
4
15.02
1
22
15.16
0.14
2.02
0
0
1
19.83
128
0
1
47
19.62
1
75
20.18
0.56
No missingness case
A known SCM allows the computation of unit-level counterfactuals: we can see both worlds at the same time. In particular, we can compute the oracle sample average treatment effect (\(^S\)ATE): the within-sample average of the individual treatment effects (unobserved in real-world data). \[
^S\text{ATE} = N^{-1}\sum_{i=1}^N \text{ITE}^{(i)} = N^{-1}\sum_{i=1}^N (Y^{(i)}_{A=1}-Y^{(i)}_{A=0})
\] The \(^S\)ATE is itself a consistent (but impossible) estimator of the population ATE (\(^P\)ATE).
Likewise, we can compute the oracle \(^S\)CATE for \(X\)-specific effects. If \(X\) is categorical, we can partition units into strata: \(I(x):=\{i\in 1\dots N : X^{(i)}=x\}\). \[
^S\text{CATE}(x) = |I(x)|^{-1}\sum_{i\in I(x)} \text{ITE}^{(i)} = |I(x)|^{-1}\sum_{i\in I(x)} (Y^{(i)}_{A=1}-Y^{(i)}_{A=0})
\]
Let us compare the oracle effects against the results from two approaches:
\(t\)-tests comparing the means of raw test scores between treated and non-treated. This estimator would be biased due to confounding
flexible libraries of base-learners to model \(A\) and \(Y\) given confounders \(H\). We employ linear models and random forests (ground-truth DGP is in this model-space)
meta-learners: to ensemble the base-learners together, weighted by their out-of-sample (CV) predictive measures to avoid over-fitting (logit for \(A\) and NNLS for \(Y\))
Code
################################################################################ Solution via t-tests (biased by confounding)################################################################################ Function to generate C.I. data from t-tests ---------------------------------# Param: pre-treatment binary variable to stratify# Return: data ready to plot as confidence intervalsget.ci.data =function(varname){# Temporal data.frame dplot1 = synth.data dplot1$dummy = dplot1[,get(varname)]# Two-sample t-test: biased! -------------------# all, med vs no-med ttest.pop =t.test(dplot1[med.6to8==1, ntr.grd8], # treated dplot1[med.6to8==0, ntr.grd8]) # control# subpop 0, med vs no-med ttest.sp0 =t.test(dplot1[med.6to8==1& dummy==0, ntr.grd8], # treated (sp 0) dplot1[med.6to8==0& dummy==0, ntr.grd8]) # control (sp 0)# subpop 1, med vs no-med ttest.sp1 =t.test(dplot1[med.6to8==1& dummy==1, ntr.grd8], # treated (sp 1) dplot1[med.6to8==0& dummy==1, ntr.grd8]) # control (sp 1)# One-sample t-test: oracle! -------------------# oracle ITE, all otest.pop =t.test(dplot1[, ITE]) # oracle ITE, subpop 0 otest.sp0 =t.test(dplot1[dummy==0, ITE]) # oracle ITE, subpop 1 otest.sp1 =t.test(dplot1[dummy==1, ITE]) # data frame put together ---------------------- dplot1 =data.table( # label for type of analysistype =rep(c('t-test','oracle'), each=3),# label for supopulationsubpop =rep(c('all','subpop 0','subpop 1'), 2), # lower boundlow =c(ttest.pop$conf.int[1], ttest.sp0$conf.int[1], ttest.sp1$conf.int[1], otest.pop$conf.int[1], otest.sp0$conf.int[1], otest.sp1$conf.int[1]),# upper boundupr =c(ttest.pop$conf.int[2], ttest.sp0$conf.int[2], ttest.sp1$conf.int[2], otest.pop$conf.int[2], otest.sp0$conf.int[2], otest.sp1$conf.int[2]))# add midpoint and return dataframe dplot1 = dplot1[, midp := (low+upr)/2] return(dplot1) }################################################################################ Solution via adjusted regression / TMLE################################################################################ Learning algorithms employed to learn treatment/outcome mechanisms -----------# Linear modellrnr_lm =make_learner(Lrnr_glm_fast)# Random forest modellrnr_rf =make_learner(Lrnr_ranger) # Meta-learners: to stack together predictions from the learners ---------------# Combine Y predictions with non-negative least squaresmeta_Y =make_learner(Lrnr_nnls) # Combine A predictions with logit likelihood (augmented Lagrange optimizer)meta_A =make_learner(Lrnr_solnp, loss_function = loss_loglik_binomial, learner_function = metalearner_logistic_binomial) # Super-learners: learners + meta-learners together ----------------------------# Outcome super-learningsuper_Y = Lrnr_sl$new(learners =list(lrnr_lm, lrnr_rf), metalearner = meta_Y)# Exposure super-learningsuper_A = Lrnr_sl$new(learners =list(lrnr_lm, lrnr_rf), metalearner = meta_A)# Super-learners put togethersuper_list =list(A = super_A,Y = super_Y) # Confounder set labelsH =colnames(synth.data[,1:6])# Function to generate C.I. data from TMLE--------------------------------------# Param: pre-treatment binary variable to stratify# Param: data# Return: data from confidence intervalsaux_tml_method =function(namevar, data=synth.data){ tmle_CATE =tmle3(tmle_spec =tmle_stratified(tmle_ATE(1,0)), # Causal contrast CATE: Y1-Y0node_list =list( # Variables involved in the queryW =setdiff(H,namevar), # Label for non-stratum confoundersV = namevar, # Label for stratifying variableA ="med.6to8", # Label for exposureY ="ntr.grd8"), # Label for outcomedata = data, # Datalearner_list = super_list) # Super-learners specifiedreturn(tmle_CATE$summary) # Return summary}################################################################################ Generate confidence intervals to plot################################################################################ t-test on prior treatmentttest.med =cbind.data.frame(get.ci.data('med.pre6'), # C.I. datastrata='prior treatment') # Strata variable# t-test on sex stratattest.sex =cbind.data.frame(get.ci.data('sex.girl'), # C.I. datastrata='sex at birth') # Strata variable# TMLE on prior treatmenttml.cate.med =aux_tml_method('med.pre6') # TMLE resultstlme.med =cbind.data.frame(type='TMLE', # method labelsubpop=c('all','subpop 0','subpop 1'), # subpop label tml.cate.med[order(tml.cate.med$param),c(9,10,8)], # C.I. datastrata='prior treatment') # Strata variable# TMLE on sex stratatml.cate.sex =aux_tml_method('sex.girl') # TMLE resultstlme.sex =cbind.data.frame(type='TMLE', # method labelsubpop=c('all','subpop 0','subpop 1'), # subpop label tml.cate.sex[order(tml.cate.sex$param),c(9,10,8)], # C.I. datastrata='sex at birth') # Strata variable# Unify column namescolnames(tlme.med) =colnames(ttest.med)colnames(tlme.sex) =colnames(ttest.sex)# Put all togetherci.data.1=rbind.data.frame(ttest.med, ttest.sex, tlme.med, tlme.sex)
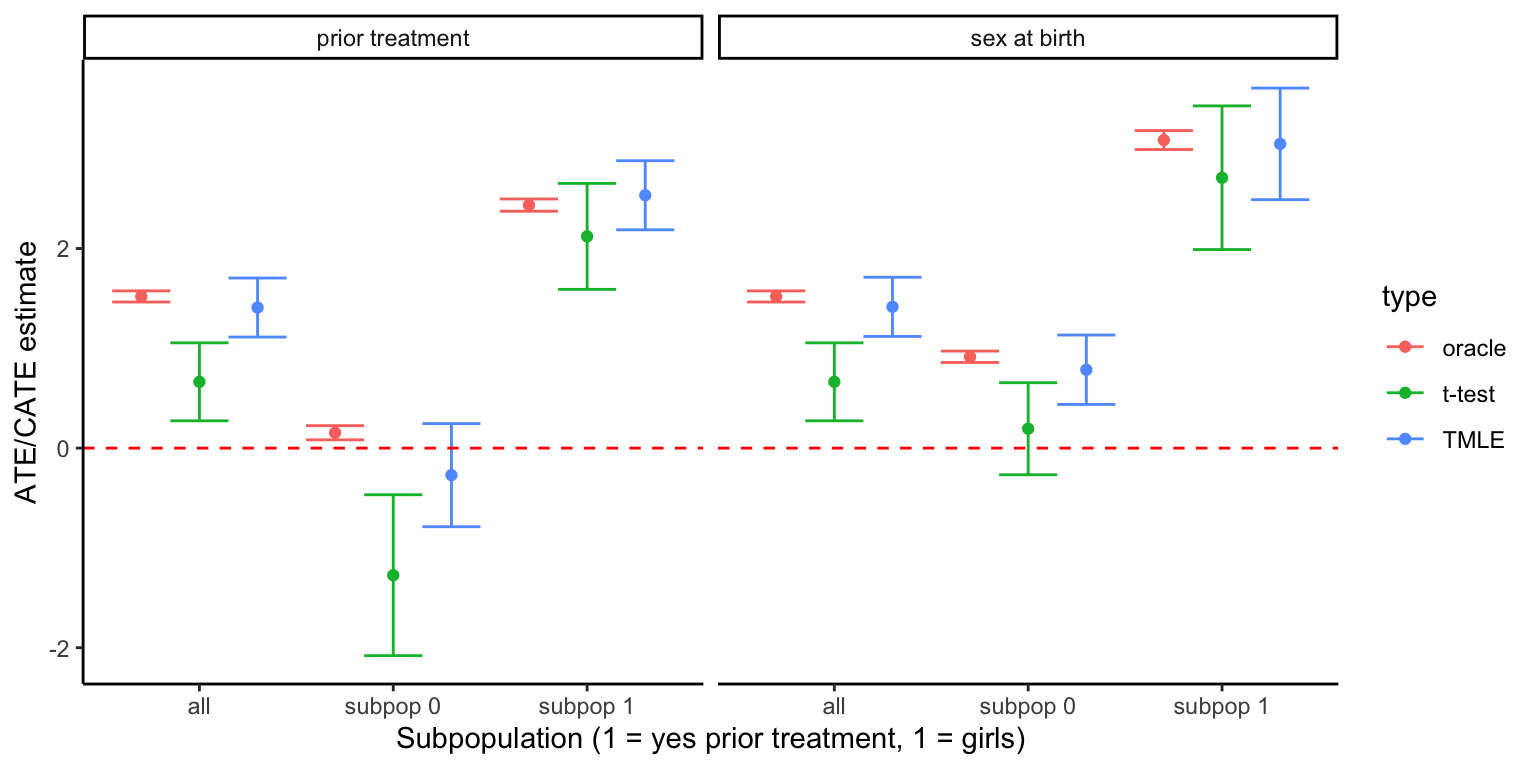
The following plot presents the point-estimate and 95% confidence interval for the ATE/CATE resulting from oracle \(^S\)ATE/\(^S\)CATE, \(t\)-tests, and TMLE.
Confidence intervals from \(t\)-tests (green) do not always cover the sample-based oracle value (red). This is probably due to confounding bias, as \(t\)-test do not adjust for covariation with \(H\)
In general, confounding bias is negative: unadjusted effects are below the oracle result
Confounding bias seems to be particularly problematic when stratifying on prior prescription for ADHD medication, which might be a strong predictor of the exposure
\(t\)-test results might lead to conclude that the treatment is actually deleterious for those who had not started it before grade 6 (because of late diagnosis?). In fact, the treatment has positive, but extremely small, average effect in such subpopulation
\(t\)-test results might also lead to conclude that the treatment effect is insignificant for boys. In fact, the effect on them is small but positive
2. TMLE with covariate adjustment
Under some mild condition including back-door admissibility of \(H\), TMLE produces consistent estimators. This is, the amount of confounding bias becomes negligible in large finite samples. We can see that confidence intervals from TMLE (blue) cover the sample-based oracle value (red) in all cases
TMLE results lead to correct interpretation of treatment effect for boys and the subpopulation who did not start treatment before grade 6
3. In general, the effects of ADHD treatment on school performance are positive but small
The estimate ATE is 1.7, on an outcome with mean 21.0 and standard deviation 7.0
Outcome-missingness mechanisms
Let us simulate the \(Y\)-missingness mechanism as a binary random variable \(R_Y\), childless in the associated \(m\)-graph \(\mathcal{G}\). For a particular individual \(i\), \(R_Y^{(i)}=1\) indicates that its respective outcome realization \(Y^{(i)}\) is observed, while \(R_Y^{(i)}=0\) signifies \(Y^{(i)}\) is missing. This mechanism has a probit specification:
\[
R_Y = \mathbb{I}[\theta_0 + \theta_H^\top H + \theta_A A + \theta_M^\top M + U_R > 0],\quad U_R\sim N(0,1)
\]
Fixing the parameters \(\theta\) to certain value (unknown in the analysis), a realization of \(U_R\) produces 751 (15%) missing outcomes:
Code
################################################################################ Building an endogenous selection/missingness mechanism################################################################################ Parameter for the glm-probit specification, only main effectsset.seed(9)noise.R =rnorm(n=5e3, 0, 1)theta.i =3.77theta.c =c(-0.01, -1.97, -2.03, 0.18, -0.03, 0.01, -0.05, 0.64, -0.01)lin.pred =as.matrix(synth.data[,1:9]) %*% theta.c + theta.i + noise.R# Realization of missingness mechanismsynth.data$RY =ifelse(lin.pred >0, 1, 0)# Count how many selected / observed -------------------------------------------table(synth.data$RY) %>%kable(col.names =c("R(Y)","n"),caption ="Table 2: Missing/selected unit-outcomes",table.attr ="quarto-disable-processing=true") %>%kable_styling(full_width =FALSE)
Table 2: Missing/selected unit-outcomes
R(Y)
n
0
751
1
4249
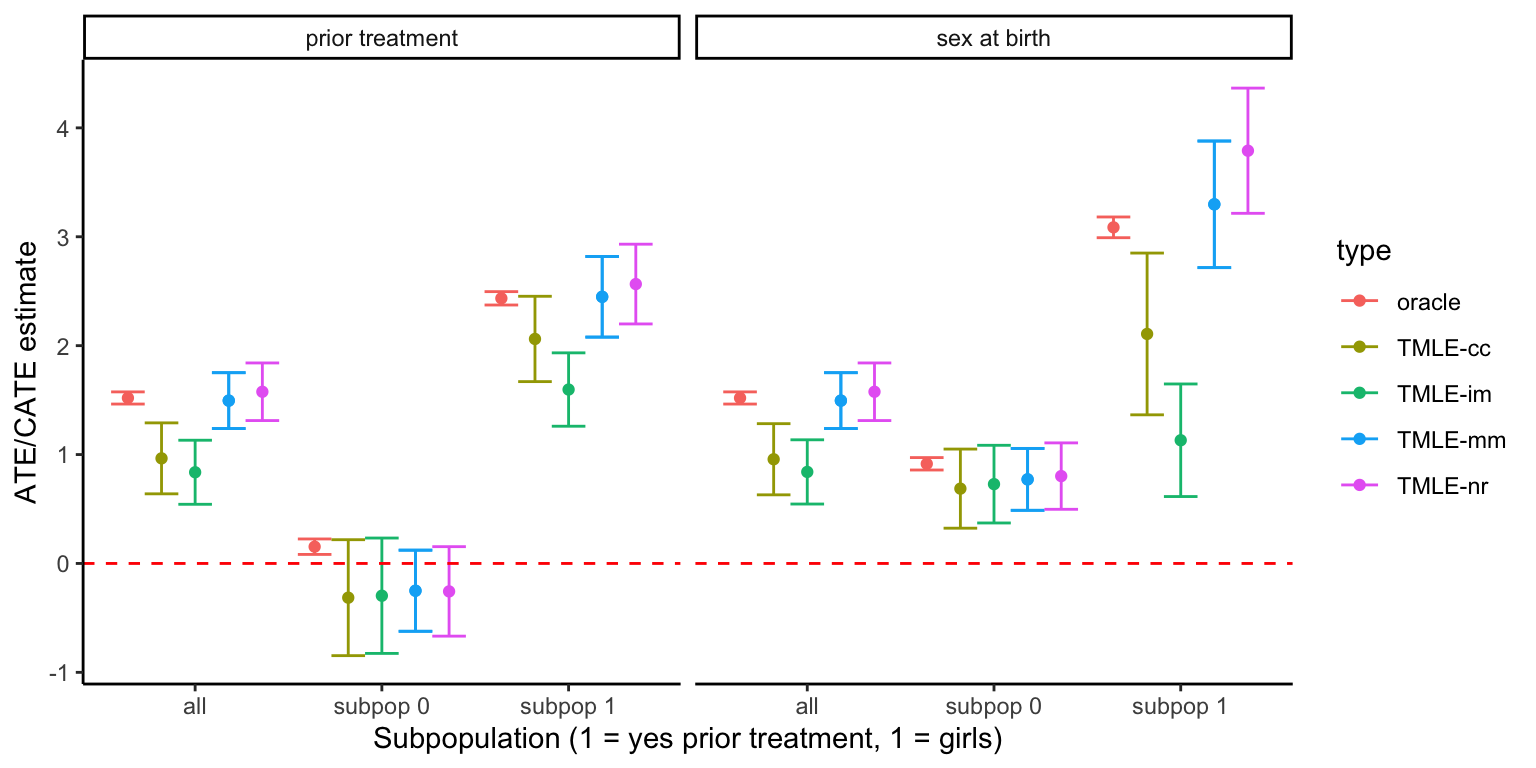
Under the TMLE framework, let us first consider four options to recover the ATE/CATE:
TMLE-cc: TMLE with complete cases. We discard entire units with \(R_Y=0\)
This approach would produce a consistent estimator under MCAR. However, as \(R_Y\) is MAR in our case, results would be biased
TMLE-im: TMLE with single median-inputation. We replace \(Y^*\) with the median of the observed \(Y\)
This approach would also produce biased results, as all missing slots are inputed with the same numeric value independen of \(H,A\). One preferable approach would be multiple model-based inputations (consistent under MAR). Yet, single median-inputation is the built-in preprocessing method in the tmle package
\[
Y^* \leftarrow \text{med}(Y\mid R_Y=1)
\]
Code
################################################################################ Median-based single imputation for missing outcome################################################################################ Replace Y-values for NA whenever R(Y)=0observed.data =copy(synth.data)observed.data$ntr.grd8 =ifelse(observed.data$RY==0, NA, observed.data$ntr.grd8)# Apply process_missing function on TMLE packageprocessed =process_missing(observed.data, # datanode_list =list(W = H, # confoundersA ="med.6to8", # exposureY ="ntr.grd8"), # outcomecomplete_nodes =c('W','A')) # complete variables# TMLE on prior treatmenttml.cate.med.im =aux_tml_method('med.pre6',data=processed$data) # TMLE resultstlme.med.im =cbind.data.frame(type='TMLE-im', # method labelsubpop=c('all','subpop 0','subpop 1'), # subpop label tml.cate.med.im[order(tml.cate.med.im$param),c(9,10,8)], # C.I. datastrata='prior treatment') # Strata variable# TMLE on sex stratatml.cate.sex.im =aux_tml_method('sex.girl',data=processed$data) # TMLE resultstlme.sex.im =cbind.data.frame(type='TMLE-im', # method labelsubpop=c('all','subpop 0','subpop 1'), # subpop label tml.cate.sex.im[order(tml.cate.sex.im$param),c(9,10,8)], # C.I. datastrata='sex at birth') # Strata variable# Unify column namescolnames(tlme.med.cc) =colnames(ttest.med)colnames(tlme.sex.cc) =colnames(ttest.sex)colnames(tlme.med.im) =colnames(ttest.med)colnames(tlme.sex.im) =colnames(ttest.sex)# Put all togetherci.data.2=rbind.data.frame(ttest.med[ttest.med$type=='oracle',], ttest.sex[ttest.sex$type=='oracle',], tlme.med.cc, tlme.sex.cc, tlme.med.im, tlme.sex.im)
TMLE-mm: TMLE with explicit model for \(M\) (only considering ptr.diag)
Let us assume we are sure that post-treatment diagnoses (ptr.diag) have a direct effect on attrition, but post-treatment visits (ptr.gpsp) do not. Since the variable ptr.diag is binary, we can pose an explicit model using a superlearner based on logistic regression. If such assumption is sound, this approach should remove most of the selection bias.
################################################################################ Recovering causal effect via regression and explicit M-model################################################################################ The library of base learners: GAM and random forestsstack = Stack$new(Lrnr_gam$new(), Lrnr_ranger$new())# Super-learner for continuous outcome: NNLSsuperl = Lrnr_sl$new(learners = stack, metalearner = Lrnr_nnls$new())# Super-learner for binary variables: default logitsuperb = Lrnr_sl$new(learners = stack)# Function to generate C.I. data from TMLE--------------------------------------# Param: pre-treatment binary variable to stratify# Param: data# Return: data from confidence intervalsaux_tml_method_mmod =function(namevar, input.data){# Remove namevar from adjustment set H =setdiff(H, namevar)# Learning the Q-function ---------------------------------------------------# Training task for Q, fit superlearner # on selected-outcome data, including M1 as predictors train.Q =make_sl3_Task(data = input.data[RY==1,],outcome ='ntr.grd8',covariates =c(H,'med.6to8','ptr.diag') ) Q_fit = superl$train(task = train.Q)# Training task for M, all data train.M =make_sl3_Task(data = input.data,outcome ='ptr.diag',covariates =c(H,'med.6to8') ) M_fit = superb$train(task = train.M)# Case A=1 ------------------------------------------------------------------# Data to make counterfactual predictions temp.dt =copy(input.data)# Prediction task for p(M=1 |A=1) temp.dt$med.6to8 =1 pred.M =make_sl3_Task(data = temp.dt,outcome ='ptr.diag',covariates =c(H,'med.6to8') ) pM = M_fit$predict(task = pred.M)# Prediction task for E(Y |A=1, M=1) temp.dt$ptr.diag =1 pred.Q1 =make_sl3_Task(data = temp.dt,outcome ='ntr.grd8',covariates =c(H,'med.6to8','ptr.diag') )# Prediction task for E(Y |A=1, M=0) temp.dt$ptr.diag =0 pred.Q0 =make_sl3_Task(data = temp.dt,outcome ='ntr.grd8',covariates =c(H,'med.6to8','ptr.diag') )# Save INTEGRAL dP(M |A=1) E(Y |A=1, M) input.data$Q_1m = pM * Q_fit$predict(task = pred.Q1) + (1-pM) * Q_fit$predict(task = pred.Q0)# Case A=0 ------------------------------------------------------------------# Prediction task for p(M=1 |A=0) temp.dt$med.6to8 =0 pred.M =make_sl3_Task(data = temp.dt,outcome ='ptr.diag',covariates =c(H,'med.6to8') ) pM = M_fit$predict(task = pred.M)# Prediction task for E(Y |A=0, M=1) temp.dt$ptr.diag =1 pred.Q1 =make_sl3_Task(data = temp.dt,outcome ='ntr.grd8',covariates =c(H,'med.6to8','ptr.diag') )# Prediction task for E(Y |A=0, M=0) temp.dt$ptr.diag =0 pred.Q0 =make_sl3_Task(data = temp.dt,outcome ='ntr.grd8',covariates =c(H,'med.6to8','ptr.diag') )# Save INTEGRAL dP(M |A=0) E(Y |A=0, M) input.data$Q_0m = pM * Q_fit$predict(task = pred.Q1) + (1-pM) * Q_fit$predict(task = pred.Q0)# Save Qm as the M-average of Q1 and Q0 input.data[,Qm := med.6to8*Q_1m + (1-med.6to8)*Q_0m]# Nuisance parameters: A ----------------------------------------------------# Training task for A, fit superlearner train.A =make_sl3_Task(data = input.data,outcome ='med.6to8',covariates = H ) A_fit = superb$train(task = train.A) input.data$p.score = A_fit$predict(task = train.A)# Nuisance parameters: R(Y) -------------------------------------------------# Training task for R(Y), fit superlearner train.R =make_sl3_Task(data = input.data,outcome ='RY',covariates =c(H,'med.6to8','ptr.diag') ) R_fit = superb$train(task = train.R) input.data$p.select = R_fit$predict(task = train.R)# Count parameters --------------------------------------------------------- N =nrow(input.data) n =nrow(input.data[RY==1,]) r = n/N# Nuisance parameters: R(Y) --------------------------------------------------- input.data[, H:= r/(p.select) * (med.6to8/p.score - (1-med.6to8)/(1-p.score)) ]# Updating model --------------------------------------------------- updating =lm(ntr.grd8 ~-1+offset(Qm) + H, data=input.data) eps =as.numeric(coef(updating))# Update Q-values input.data[, Q_1f:= Q_1m + eps * r/(p.select*p.score)] input.data[, Q_0f:= Q_0m - eps * r/(p.select*(1-p.score))] input.data[, D:= H*(ntr.grd8 - Qm) + Q_1m - Q_0m]# Compute ATE, standard errors and CI ate =mean(input.data$Q_1f - input.data$Q_0f) ate.se =sd(input.data$D, na.rm=T)/sqrt(n) ate.lo = ate -qnorm(0.975)*ate.se ate.up = ate +qnorm(0.975)*ate.se# Return CIreturn(c(ate.lo, ate.up, ate))}# Generate CI dataate =aux_tml_method_mmod('', observed.data)cate.nop =aux_tml_method_mmod('med.pre6', observed.data[med.pre6==0,])cate.yes =aux_tml_method_mmod('med.pre6', observed.data[med.pre6==1,])cate.boy =aux_tml_method_mmod('sex.girl', observed.data[sex.girl==0,])cate.grl =aux_tml_method_mmod('sex.girl', observed.data[sex.girl==1,])# Put all togetherci.data.3= ci.data[13:18,]ci.data.3$type ='TMLE-mm'ci.data.3$midp =c(ate[3], cate.nop[3], cate.yes[3], ate[3], cate.boy[3], cate.grl[3])ci.data.3$low =c(ate[1], cate.nop[1], cate.yes[1], ate[1], cate.boy[1], cate.grl[1])ci.data.3$upr =c(ate[2], cate.nop[2], cate.yes[2], ate[2], cate.boy[2], cate.grl[2])
TMLE-nr: TMLE with nested regressions.
Let us assume we are sure that post-treatment diagnoses (ptr.diag) have a direct effect on attrition, but post-treatment visits (ptr.gpsp) do not. Since the variable ptr.diag is binary, we can pose an explicit model using a superlearner based on logistic regression. If such assumption is sound, this approach should remove most of the selection bias.
Confidence intervals from complete-case analysis (brown) and single median-inputations (green) fail to cover the oracle SATE (red) in most cases, particularly for the population ATE.
A regression-based solution via an explicit model for ptr.diag (blue) does a better job, and only struggle with small subpopulations in the data (no prior treatment or girls, about 30%).
A nested-regressions approach (purple) performs well for the ATE, but struggle a little with small subpopulations.
All methods above via TMLE employ only one fluctuation parameter (on \(Q_2\)). Better performance can be obtained by working with a fluctuation parameter on \(Q_1\) or \(p(M\mid H,A)\) as well, and by incorporating smart cross-fitting schemes.
Phillips, Rachael V, Mark J van der Laan, Hana Lee, and Susan Gruber. 2023. “Practical considerations for specifying a super learner.”International Journal of Epidemiology 52 (4): 1276–85. https://doi.org/10.1093/ije/dyad023.
van der Laan, M. J., and S. Rose. 2011. Targeted Learning: Causal Inference for Observational and Experimental Data. Springer Series in Statistics. Springer New York. https://books.google.no/books?id=RGnSX5aCAgQC.